LLVM中的IR
记录学习LLVM IR的过程!
LLVM中的IR
LLVM中的IR,即Intermediate Representation(中间表示),是LLVM编译器基础设施中的核心组件。 它是一种低级别的、类型丰富的、与平台无关的中间语言,用于在整个编译过程中表示程序。IR设计得既适合于人类阅读, 也适合于机器操作。
其实就是为了方便优化所设计的一种代码在编译过程中间的表示形式。
1、IR的特点
- 1)、采用静态单赋值(SSA)形式,SSA的要求很简单:每个变量只被赋值一次。
- 2)、它以三地址指令组织代码。数据处理指令有两个源操作数,有一个目标操作数以存放结果。
- 3)、有无限数量的寄存器。注意LLVM局部值可以命名为任意以%符号开头的名字,包括从0开始的数字,例如%0,%1,等等,不限制不同的值的最大数量。
2、IR的layout
从顶层到底层分为:module(模块)、function(函数)、basic block(基本块)、instruction(指令)。如下图所示,是一个简单的.ll格式的IR:
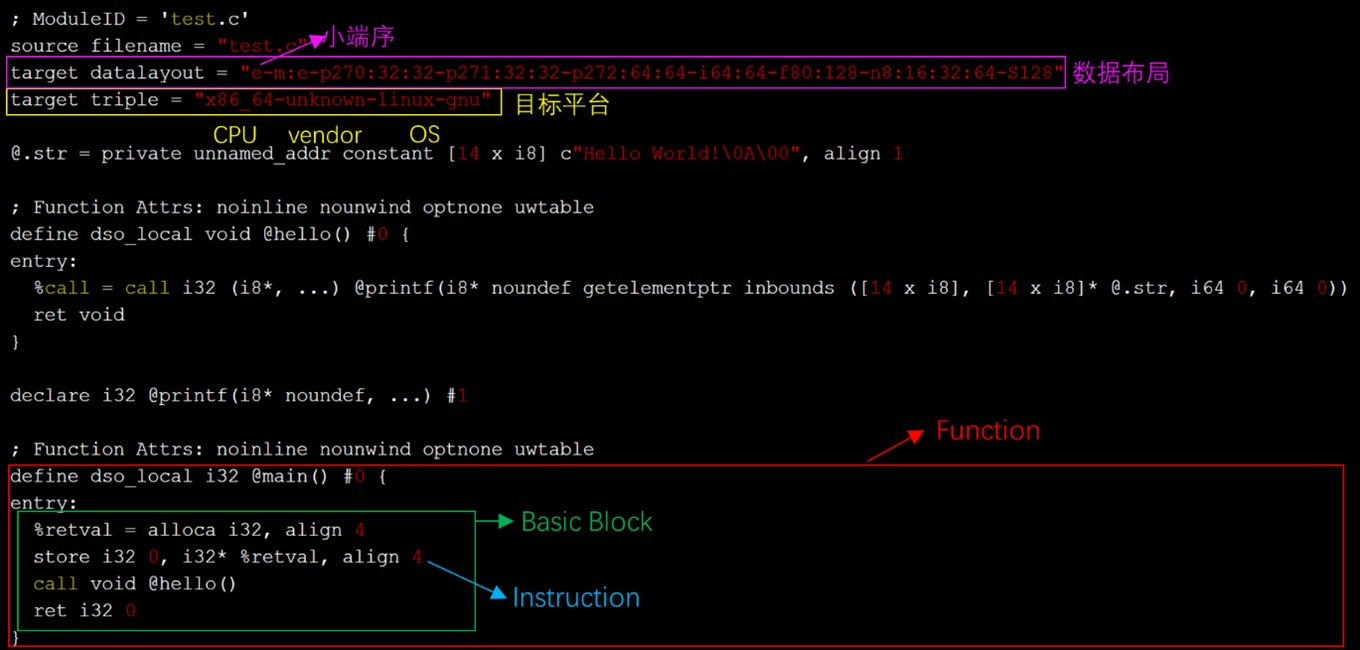
开始为moduleID,然后下边的为一些目标信息,包括数据布局以及目标平台的信息,具体的含义为:
- 1)、CPU–vendor–OS:这三者决定了一个平台,只要这三者一致,我们生成的二进制程序往往就可以确定了。这三者就被称为一个「目标三元组」(Target Triple)。
- 2)、target datalayout:这一长串文字就定义了目标的数据布局。具体而言:
• e: 小端序
• m:e: 符号表中使用ELF格式的命名修饰
• p270:32:32-p271:32:32-p272:64:64: 与地址空间有关
• i64:64: 将i64类型的变量采用64位的ABI对齐
• f80:128: 将long double类型的变量采用128位的ABI对齐
• n8:16:32:64: 目标CPU的原生整型包含8位、16位、32位和64位
• S128: 栈以128位自然对齐
注解是以 ; 分隔且直到当前行的结尾,所以; Function Attrs: noinline nounwind optnone uwtable这一行是注解。 接下来就是Function、Basic Block以及Instruction。
3、数据区与符号表
数据区里的数据,其最大的特点就是,能够给整个程序的任何一个地方使用。同时,数据区里的数据也是占静态的二进制可执行程序的体积的。所以,我们应该只将需要全程序使用的变量放在数据区中。而现代编程语言的经验告诉我们,这类全局静态变量应该越少越好。 在LLVM IR中,所有的全局变量的名称都需要用@开头。 一般来说,在LLVM IR中定义一个存储在数据区中的全局变量,其格式为:@global_variable = global i32 0,这个语句定义了一个i32类型的全局变量@global_variable,并且将其初始化为0。如果是只读的全局变量,也就是常量,我们可以用constant来代替global:@global_constant = constant i32 0,这个语句定义了一个i32类型的全局常量@global_constant,并将其初始化为0。 粗略来讲,整体的符号处理的过程为:
- 1)、编译器对源代码按文件进行编译。对于每个文件中的未知函数,记录其符号;对于这个文件中实现的函数,暴露其符号
- 2)、链接器收集所有的目标文件,对于每个文件而言,将其记录下的未知函数的符号,与其他文件中暴露出的符号相对比,如果找到匹配的,就成功地解析(resolve)了符号
- 3)、部分符号在程序加载、执行时,由动态链接库给出。动态链接器将在这些阶段,进行类似的符号解析。
默认的为external,变量会被放到符号表中,若改为:@global_variable = private global i32 0,那么变量不会被放到符号表中。用internal则表示这个变量是以局部符号的身份出现(全局变量的局部符号,可以理解成C中的static关键词)。我们将原来的代码改写成:@global_variable = internal global i32 0,变量会被放到符号表中,但是在链接过程中,这个符号不参与符号解析。
4、数据的使用
LLVM的IR是强类型的语言,使用强类型的语言,LLVM IR可以更好的进行优化,LLVM IR中比较基本的数据类型包括:
• 空类型(void)
• 整型(iN)
• 浮点型(half 16位浮点值
float 32位浮点值
double 64位浮点值
fp128 128位浮点值(112位尾数)
x86_fp80 80位浮点值(X87)
ppc_fp128 128位浮点值(两个64位))
IR的全局变量与栈上变量皆指针,也就是说,对于全局变量:@global_variable = global i32 0,和栈上变量:%local_variable = alloca i32,这两个变量实际上都是ptr指针,指向它们所处的一个i32大小的内存区域。
所以,我们不能这样:%1 = add i32 1, @global_variable ; Wrong!
因为@global_variable只是一个指针。如果要操作这些值,必须使用load和store这两个命令。如果我们要获取@global_variable的值,就需要:%1 = load i32, ptr @global_variable,这个指令的意思是,把一个ptr指针@global_variable的i32类型的值赋给虚拟寄存器%1,然后我们就能执行%2 = add i32 1, %1。类似地,如果我们要将值存储到全局变量或栈上变量里,会需要store命令:store i32 1, ptr @global_variable。
5、聚合类型
比起指针类型而言,更重要的是聚合类型。我们在C语言中常见的聚合类型有数组和结构体,LLVM IR也为我们提供了相应的支持。数组类型很简单,我们要声明一个类似C语言中的int a[4],只需要%a = alloca [4 x i32],也就是说,C语言中的int[4]类型在LLVM IR中可以写成[4 x i32]。注意,这里面是个x不是*。
我们也可以使用类似地语法进行初始化:@global_array = global [4 x i32] [i32 0, i32 1, i32 2, i32 3]。特别地,我们知道,字符串在底层可以看作字符组成的数组,所以LLVM IR为我们提供了语法糖:@global_string = global [12 x i8] c”Hello world\00”。在字符串中,转义字符必须以\xy的形式出现,其中xy是这个转义字符的ASCII码。比如说,字符串的结尾,C语言中的\0,在LLVM IR中就表现为\00。
结构体的类型也相对比较简单,在C语言中的结构体:
struct MyStruct {
int x;
char y;
};
在LLVM IR中就成了:
%MyStruct = type {
i32,
i8
}
我们初始化一个结构体也很简单:@global_structure = global %MyStruct { i32 1, i8 0 }; 或者@global_structure = global { i32, i8 } { i32 1, i8 0 }。值得注意的是,无论是数组还是结构体,其作为全局变量或栈上变量,依然是指针,也就是说,@global_array的类型是ptr, @global_structure的类型也是ptr。
参考来源
https://evian-zhang.github.io/llvm-ir-tutorial/
https://getting-started-with-llvm-core-libraries-zh-cn.readthedocs.io/zh-cn/latest/