LLVM中的LTO
记录学习LLVM中的LTO的过程!
LLVM中的LTO(Link-Time Optimization)
1、什么是LTO
链接时优化(Link-Time Optimization, LTO)是链接期间的程序优化。由于编译器一次只编译优化一个编译单元,因此在编译期的很多优化都难以跨编译单元执行,只是在做局部的优化。LTO 就是对整个程序代码进行的一种优化,在链接时将多个中间文件通过链接器合并在一起,进行跨模块间的优化。LTO 聚焦分析整个程序代码,能够大范围地应用过程间优化,从而取得比较好的优化效果,还能够缩减代码体积。
2、LTO的使用方式
llvm中使用LTO的方式如下所示:
1
2
3
clang -flto -c a.c -o a.o # <-- a.o is LLVM bitcode file
clang -c main.c -o main.o # <-- main.o is native object file
clang -flto a.o main.o -o main # <-- standard link command with -flto
在源文件编译时,添加-flto编译选项,这样编译出的.o文件不是目标文件,而是bitcode类型的文件。在链接的时候,lld识别到bitcode类型的输入文件,自动开启LTO。
3、LTO的执行流程
LTO的核心原理是在链接阶段进行全局优化。正常链接与使用LTO的基本流程对比如下: 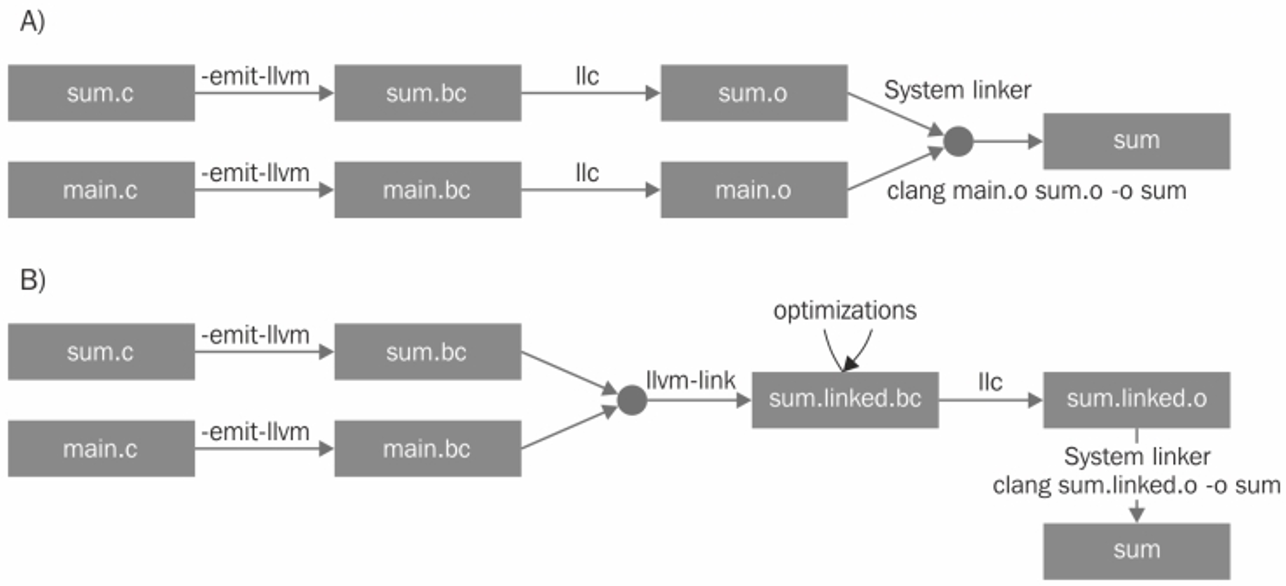 图中的
图中的
- A) 是正常的编译链接过程: 编译过程中直接生成目标文件;使用链接器将目标文件链接成可执行文件。
- B)则是使用了LTO的执行过程: 编译生成带有中间表示的目标文件:编译器在编译源文件时,会将每个编译单元(如C/C++中的源文件)生成为包含编译器中间表示(Intermediate Representation,IR)的目标文件。 链接时进行全局优化:在链接阶段,链接器会将所有包含IR的目标文件进行合并,并对整个程序进行全局优化,如去除冗余代码、内联函数等。 生成优化后的目标文件并链接成可执行文件:在生成优化后的目标文件后,链接器将目标文件链接成可执行文件,提高程序的执行效率。
4、LTO的分类
LLVM支持两种模式的 LTO,分别是 FullLTO 和 ThinLTO。
- 1)、FullLTO
我们常用的选项-flto其实代表-flto=full,FullLTO 模式指LTO将分散的目标文件的所有LLVM IR组合到一个大的LLVM模块中,然后对其进行整体分析优化。上述编译选项是host端代码编译时的,device端代码的编译选项为:-foffload-lto=full,FullLTO 模式执行流程如下图所示: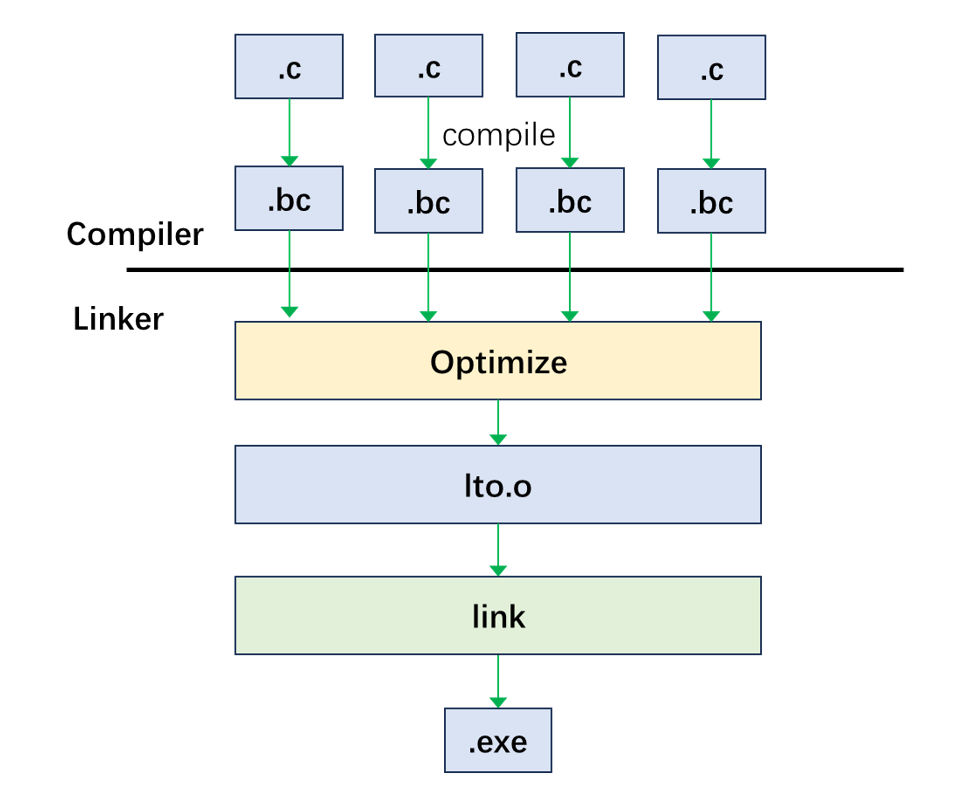 如图中所示,源文件在编译成bitcode格式的文件后,会在链接时合并一个文件,LTO串行的对这一个文件进行优化,并将LTO生成的目标文件继续做链接。FullLTO 的实现是把所有的输入合并到一个模块,并没有考虑时间和内存的问题,而且还阻碍了增量编译的执行。这意味着 FullLTO 经常需要大量的内存,而且很慢。当源码改变时,FullLTO 的所有步骤都需要被重新执行。
如图中所示,源文件在编译成bitcode格式的文件后,会在链接时合并一个文件,LTO串行的对这一个文件进行优化,并将LTO生成的目标文件继续做链接。FullLTO 的实现是把所有的输入合并到一个模块,并没有考虑时间和内存的问题,而且还阻碍了增量编译的执行。这意味着 FullLTO 经常需要大量的内存,而且很慢。当源码改变时,FullLTO 的所有步骤都需要被重新执行。 2)、ThinLTO
为了解决FullLTO的弊端,提出了ThinLTO模式。host端代码添加编译选项-flto=thin开启ThinLTO模式,device端代码添加-foffload-lto=thin开启ThinLTO模式。ThinLTO 模式的执行流程如下图所示: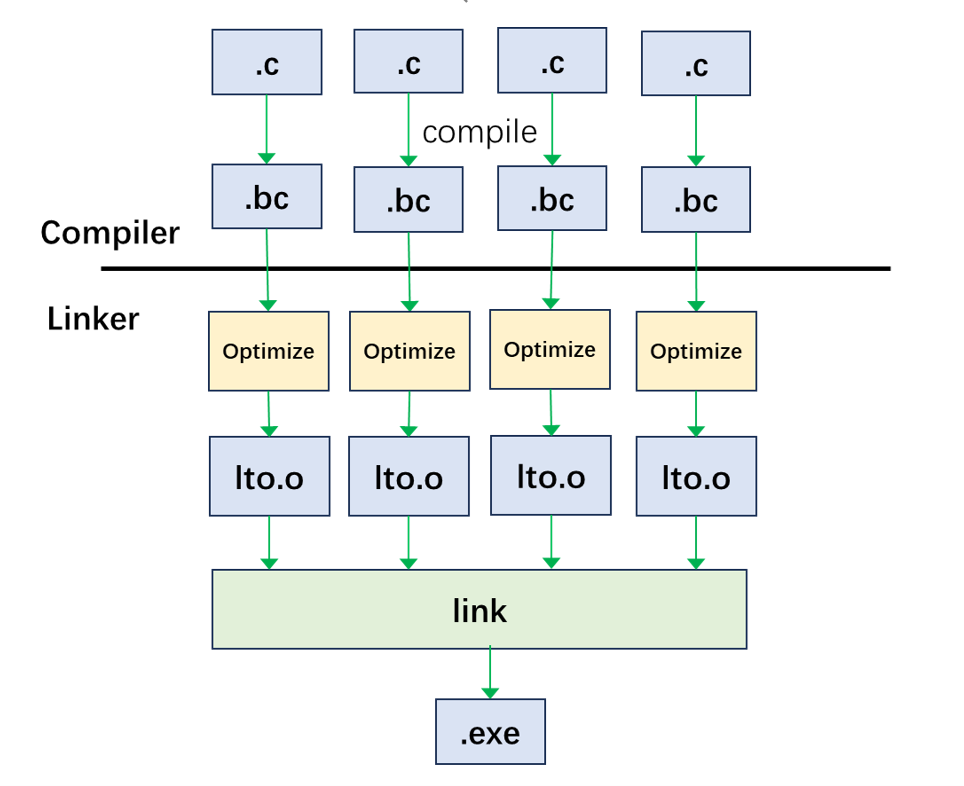 如图中所示,编译器将源文件编译为bitcode格式的文件,在执行链接时优化时,ThinLTO模式不会将所有的输入文件合并成一个文件,而是并行的在每个编译单元中执行优化,根据需要才从其他模块导入功能,并且除全局分析外均采用并行的方式进行优化。因此使用-flto=thin比-flto=full编译链接的速度大大加快,这个模式可以允许更快的增量编译,以及使用更少的内存。
如图中所示,编译器将源文件编译为bitcode格式的文件,在执行链接时优化时,ThinLTO模式不会将所有的输入文件合并成一个文件,而是并行的在每个编译单元中执行优化,根据需要才从其他模块导入功能,并且除全局分析外均采用并行的方式进行优化。因此使用-flto=thin比-flto=full编译链接的速度大大加快,这个模式可以允许更快的增量编译,以及使用更少的内存。从优化能力上看,FullLTO 要比 ThinLTO 获得更好的优化效果,同时编译时长也会变得更长。而ThinLTO采用了并行的设计方式,因此要比FullLTO的链接速度要快。为了提高FullLTO的速度,可以使用–lto-partitions=
或者--plugin-opt=lto-partitions= (https://discourse.llvm.org/t/improving-the-link-time-of-lto/75132/2)设置LTO的分块数量实现codegen部分的并行加速,具体的实现方式在以下链接中有详细说明:
⚙ D95222 [LTO] 更新 splitCodeGen 以引用该模块。(NFC) (llvm.org);
⚙ D18999 [ELF/LTO] 用于 LLD 的并行代码生成 (llvm.org)
- 3)、识别过程
lld默认使用的是FullLTO,也就是说只要不开启ThinLTO,所有的bitcode文件是会全部合在一起串行优化的。这个识别的过程是在添加bitcode文件的时候对文件进行解析,每个module设置一个LTOInfo,用来获取当前module的LTO信息。具体是在\llvm\lib\Bitcode\Reader\BitcodeReader.cpp文件中的getLTOInfo()函数进行识别: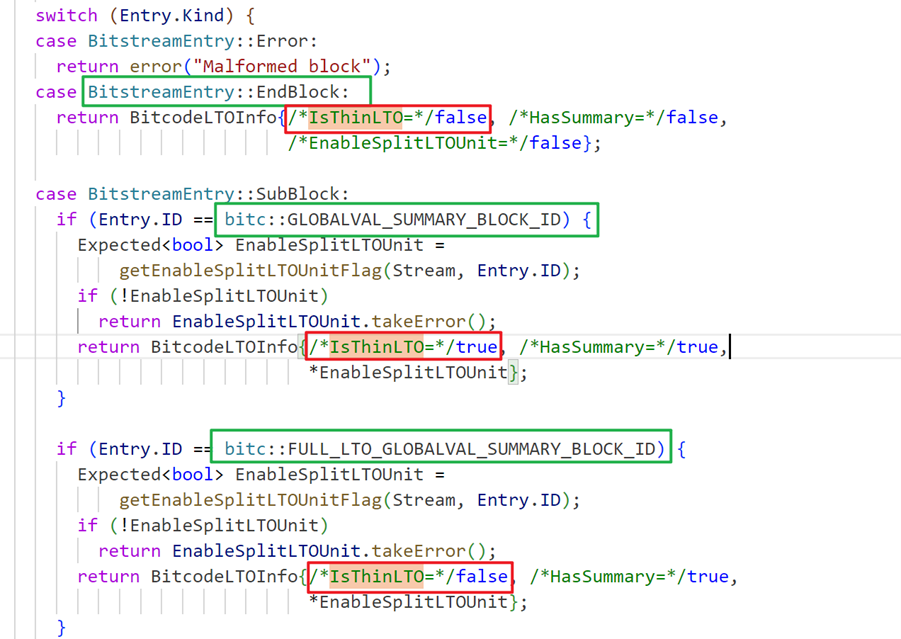 这个函数的作用就是检查给定的位代码缓冲区是否包含全局值摘要块。通过标识位IsThinLTO记录,默认IsThinLTO为false,若有bitcode文件中存在ID为FULL_LTO_GLOBALVAL_SUMMARY_BLOCK_ID说明为FullLTO,IsThinLTO为false:
这个函数的作用就是检查给定的位代码缓冲区是否包含全局值摘要块。通过标识位IsThinLTO记录,默认IsThinLTO为false,若有bitcode文件中存在ID为FULL_LTO_GLOBALVAL_SUMMARY_BLOCK_ID说明为FullLTO,IsThinLTO为false: 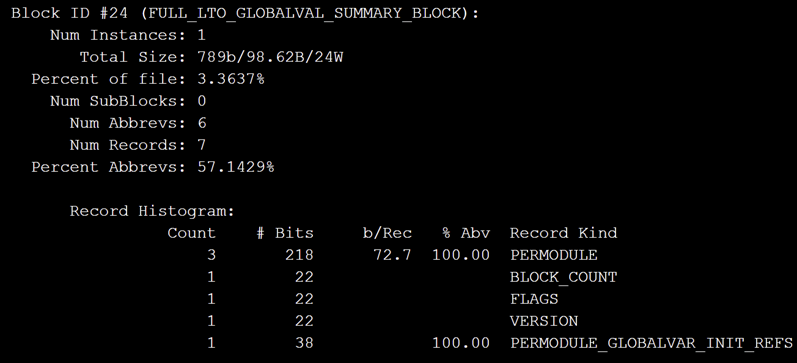 若为GLOBALVAL_SUMMARY_BLOCK_ID则说明为ThinLTO,IsThinLTO为true,根据IsThinLTO的值加载对应的LTO:
若为GLOBALVAL_SUMMARY_BLOCK_ID则说明为ThinLTO,IsThinLTO为true,根据IsThinLTO的值加载对应的LTO: 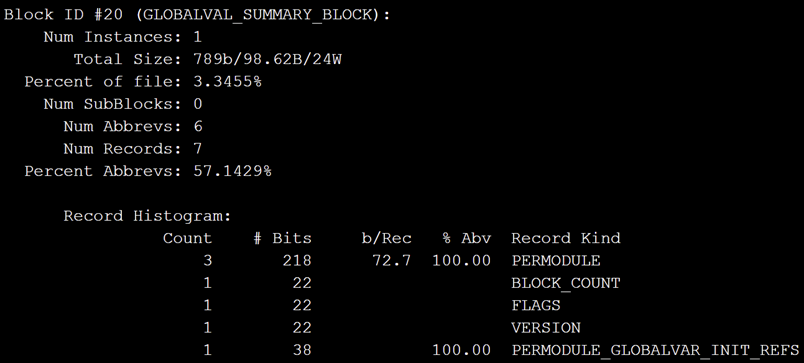
5、总结
LTO是一种优化技术,旨在解决源代码编译期间,因只能优化本编译单元的内容而忽视了整体的优化机会导致的性能受限问题。使用LTO后,单个编译单元在编译期间依旧会做优化,但是会缺少CodeGen的相关pass,这部分被放在链接阶段进行。在链接时会对所有编译单元整体再进行优化。链接时能够看到程序的整体情况,方便跨编译单元在整体上做优化,因此性能会更好。但是也因为需要把所有bitcode都读到内存里,同时要在所有的bitcode里执行链接和优化,也不能执行增量编译,所以编译的速度会很慢,内存的需求也更大。
一般来说只要在链接的时候有bitcode文件,就会开启LTO,默认的为FullLTO,只有在编译源文件的时候开启-flto=thin(host端代码)或者-foffload-lto=thin(device端代码),才会在lld中被识别到ThinLTO的block_id,开启ThinLTO。
LTO的主要作用总结如下:
- 1)将一些函数内联化。
- 2)去除了一些无用代码。
- 3)对程序有全局的优化作用。
参考来源
https://llvm.org/docs/LinkTimeOptimization.html
https://blog.csdn.net/dashuniuniu/article/details/122769486
https://blog.csdn.net/dashuniuniu/article/details/122807374
https://zhuanlan.zhihu.com/p/696403628
https://www.cnblogs.com/wujianming-110117/p/17653181.html
https://calssion.netlify.app/post/opt/lto/